Amazon Athena におけるプリペアドステートメント活用ガイド
この記事は はてなエンジニア Advent Calendar 2025 の12月30日の記事です。
はじめに
アプリケーション開発者にとって、SQL インジェクションを防ぐ プリペアドステートメント は馴染みのある仕組みです。
Athena (Trino ベースのエンジン) もこの標準に準拠しており、? をプレースホルダーとして使用するプリペアドステートメントをサポートしています。AWS のドキュメントでは「parameterized queries (パラメータ化されたクエリ)」と呼ばれていますが、一般的な RDBMS におけるプリペアドステートメントと同じ仕組みです。
本記事では、この手法を用いてクエリを実行する方法を AWS SDK の実例と共に解説します。
データ分析で直面する課題
アプリケーションから Athena を利用する際、開発者が直面するのが以下の課題です。
- セキュリティリスク: ユーザー入力を文字列操作で直接クエリに埋め込むことは、SQL インジェクションのリスクを招きます。
- パフォーマンス: 同じ構造のクエリであっても毎回ゼロから解析処理が行われるため、実行開始までのオーバーヘッドが発生してしまいます。
そこで使えるのがプリペアドステートメント (パラメータ化されたクエリ) です。
マネジメントコンソールでの実行イメージ
まずはイメージを掴むため、AWS マネジメントコンソールのクエリエディタでの挙動を見てみましょう。

このように、SQL クエリの構文 (ロジック) とパラメータ値 (データ) が明確に分かれていることがわかります。
SDK での実装方法
Athena の StartQueryExecution API では、パラメータを ExecutionParameters という配列で渡します。
import boto3 athena = boto3.client('athena', region_name='ap-northeast-1') database_name = 'your_database' query_result_location = 's3://athena-result/' # 文字列リテラルとして扱うため、シングルクォート(')を含める date_from = "'2026/01/01'" status_code = '200' response = athena.start_query_execution( QueryString=""" SELECT date, time, elb_status_code FROM your_table WHERE date >= ? AND elb_status_code = ? LIMIT 10; """, QueryExecutionContext={'Database': database_name}, ResultConfiguration={'OutputLocation': query_result_location}, ExecutionParameters=[date_from, status_code] ) query_id = response['QueryExecutionId'] print(f"Query started: {query_id}")
文字列型や日付型の場合は、値自体にクォートを含めて渡す必要があります。一般的な SQL クエリとは異なり、Athena では値を自動でクォートしないため、そのまま渡すと TYPE_MISMATCH: line 5:12: Cannot apply operator: varchar = integer というようなエラーになってしまいます。
上記のコードではシングルクォートで囲い "'2026/01/01'" としましたが、扱いづらい仕様なので本番ではヘルパー関数を作ると可読性が上がるかと思います。
まとめ
特に、Lambda や Fargate 、Step Functions などで繰り返しクエリを実行する場面で効果を発揮すると思うので、ぜひ使ってみてください。
参考
Amazon ECS FireLens でタスク ID をログに含める方法 - Classic mode 編
概要
Amazon ECS (以下、 ECS) におけるログ管理では、FireLens と AWS For Fluent Bit を組み合わせた構成が広く採用されています1。この構成により、 AWSLogs ドライバーでは実現できない柔軟なログルーティングとカスタマイズが可能になります。
しかし、ログ分析やトラブルシューティングにおいて、特定のタスクを識別するためのタスク ID が直接的には取得できないという課題があります。FireLens はデフォルトでタスク ARN を提供しますが、多くの運用シナリオではタスク ID そのものが必要になります。
この記事では、Fluent Bit の設定をカスタマイズして、ログにタスク ID を含める方法を解説します。
前提
Fluent Bit のコンフィグには YAML と Classic mode の 2 種類の形式があります。本記事では、現在も広く使用されている Classic mode 形式での設定例を紹介します。
注意: Classic mode 形式は 2026 年末に非推奨となる予定です2。新規プロジェクトでは YAML 形式の採用を検討することをお勧めしますが、既存環境での実装や学習目的では、Classic mode 形式も有効です。
課題の詳細
FireLens は、ECS タスクのログにクラスター名やタスク ARN といったメタデータをデフォルトで付与します3。
しかし、タスク ID そのものは独立したフィールドとして提供されません。
また、 ECS Filter という Fluent Bit のプラグインがありますが、EC2 起動タイプでのみ機能し、 Fargate 起動タイプでは利用できません。
これにより、以下のような運用上の課題が発生します:
- ログ分析ツールでタスク ID の検索・集計が困難
- トラブルシューティング時のタスク特定に手間がかかる
例えば、CloudWatch Logs で特定のタスクのログを検索する際、タスク ARN 全体での検索が必要となり、クエリが複雑になってしまいます。
解決方法: Fluent Bit によるタスク ID 抽出
この課題を解決するため、Fluent Bit のフィルター機能を使用してタスク ARN からタスク ID を抽出し、独立したフィールドとして追加する方法を実装します。
アプローチの概要
既存の FireLens 機能を活用しながらタスク ID を取得します。
- FireLens が提供する
ecs_task_arnフィールドを取得 - Fluent Bit の正規表現フィルターでタスク ID を抽出
- 新しいフィールド
ecs_task_idとしてログレコードに追加
タスクARN 形式
ECS タスク ARN には、アカウント設定により 2 つの形式が存在します4:
- 従来形式:
arn:aws:ecs:region:aws_account_id:task/task-id - 新形式:
arn:aws:ecs:region:aws_account_id:task/cluster-name/task-id
どちらの形式でも、最後のスラッシュ (/) 以降がタスク ID であることがポイントです。
コンフィグ例
パーサー
タスク ARN をパースしてタスク ID を取得するコンフィグは次のようになります。
[PARSER]
Name ecs_task_id
Format regex
Regex .*\/(?<ecs_task_id>[^\/]+)$
正規表現の解説:
.*\/: 文字列の先頭から一番最後の/までにマッチ (貪欲マッチ)(?<ecs_task_id>[^\/]+):ecs_task_idという名前付きキャプチャグループで、最後の/以降の、/を含まない 1 文字以上の文字列 (つまりタスク ID) を取得。これにより新形式と従来形式の ARN 両方に対応$: 文字列の終端を示す
フィルター
次のように Filter から呼び出します。これにより、 ecs_task_id というフィールドがログに追加されます。
[FILTER]
Name parser
Match *-firelens-*
Key_Name ecs_task_arn
Parser ecs_task_id
Reserve_Data true
Preserve_Key true
結果
ログをクエリして、ログにタスク ID (ecs_task_id 列) が正しく追加されることを確認しました。
SELECT dt, ecs_task_id FROM logs WHERE dt > '2025/10/01' LIMIT 10;

おわりに
この記事では、 ECS の FireLens において、タスク ID をログに含める実践的な方法を詳しく解説しました。
今後 AWS For Fluent Bit v3.0.0 を検証して YAML 編も出すかもしれません。
参考
実装
OpenTelemetry Collector の Resource Detection Processor の実装を参考にしました。この実装でもタスク ARN をパースしてタスク ID を取得しています。
// Parses ECS Task ARN into subcomponents according to its spec // See: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-account-settings.html#ecs-resource-ids func parseTaskARN(taskARN string) (region, account, taskID string) { parts := strings.Split(taskARN, ":") if len(parts) >= 5 { region := parts[3] account := parts[4] // ECS Task ARNs come in two versions. In the old one, the last part of the ARN contains // only the "task/<task-id>". In the new one, it contains "task/cluster-name/task-id". // This handles both cases. taskInfo := parts[5] taskInfoParts := strings.Split(taskInfo, "/") taskID := taskInfoParts[len(taskInfoParts)-1] return region, account, taskID } return "", "", "" }
ドキュメント
- Using custom log routing with FireLens for Amazon ECS - AWS Prescriptive Guidance↩
- Fluent Bit Classic Mode Configuration↩
- Example Amazon ECS task definition: Route logs to FireLens - Amazon Elastic Container Service↩
- Access Amazon ECS features with account settings - Amazon Elastic Container Service↩
Terraform cloudinit Provider を使って MIME multi-part 形式の cloud-init 設定を管理する
概要
この記事では、Terraform の cloudinit Provider を紹介します。
まず、 cloud-init の MIME multi-part 形式を説明した後、この Provider を使った Amazon EC2 の IaC (Infrastructure as Code) を紹介します。
前提
以下のバージョンを参考にしています。
cloud-init の MIME multi-part 形式
まずはじめに、 cloud-init の MIME multi-part 形式について説明します。
MIME multi-part 形式とは、異なる複数のタイプを組み合わせることができる形式です。
例えば、 text/cloud-config (Cloud-config) と text/x-shellscript (ユーザーデータスクリプト) を組み合わせることができます。
MIME multi-part の設定例
Content-Type: multipart/mixed; boundary="===============2389165605550749110==" MIME-Version: 1.0 Number-Attachments: 2 --===============2389165605550749110== Content-Type: text/cloud-boothook; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="part-001" #!/bin/sh echo "this is from a boothook." > /var/tmp/boothook.txt --===============2389165605550749110== Content-Type: text/cloud-config; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="part-002" bootcmd: - echo "this is from a cloud-config." > /var/tmp/bootcmd.txt --===============2389165605550749110==--
User-data formats - cloud-init 25.3 documentation
MIME multi-part 形式の課題
MIME multi-part は便利ですが、上記に示した例のように人間が読むには複雑です。
そこで、 Terraform の cloudinit Provider が役立ちます。
Terraform cloudinit Provider
cloudinit Provider は、 cloud-init の設定パーツを Terraform のコードとして記述し、自動で MIME multi-part 形式にレンダリングしてくれるデータソースを提供します。
この Provider は HashiCorp 公式で、すぐに利用できます。
Amazon EC2 の user_data で使う例
ここからは Amazon EC2 (以下、 EC2) を使った Terraform コード例を紹介します。
EC2 は cloud-init をサポートしています。
ここでは、次のようなモジュール構成を想定します。
.
└── modules
└── compute
├── files
│ ├── cloud-config.yaml
│ └── script.sh
└── main.tf
compute モジュール:
1. Cloud-config 形式のファイルの作成
パッケージの更新と git のインストールを行います。
modules/compute/files/cloud-config.yaml
#cloud-config package_update: true package_upgrade: true packages: - git
2. ユーザーデータスクリプトの作成
簡単なログを出力するスクリプトです。
modules/compute/files/script.sh
#!/bin/sh set -e echo "Hello from cloud-init shellscript part!" >> /tmp/cloud-init-log.txt
3. cloudinit_config データソースの設定と EC2 への適用
cloudinit_config データソースを使って files ディレクトリの 2 つのファイルを結合し、 EC2 インスタンスのユーザーデータに渡します。
modules/compute/main.tf (cloud-init に関連する部分を抜粋)
data "cloudinit_config" "this" { # EC2 ユーザーデータは 16KB の制限があるため、データサイズを削減するとよい gzip = true base64_encode = true # ユーザーデータスクリプト part { filename = "script.sh" content_type = "text/x-shellscript" content = file("${path.module}/files/script.sh") } # Cloud-config part { filename = "cloud-config.yaml" content_type = "text/cloud-config" content = file("${path.module}/files/cloud-config.yaml") } } data "aws_ssm_parameter" "amazon_linux_2023" { name = "/aws/service/ami-amazon-linux-latest/al2023-ami-kernel-6.12-arm64" } resource "aws_instance" "this" { ami = data.aws_ssm_parameter.amazon_linux_2023.value instance_type = "t4g.small" # レンダリングされた user_data を渡す user_data_base64 = data.cloudinit_config.this.rendered # user_data の変更時にインスタンスを再作成 user_data_replace_on_change = true # 必要に応じてセキュリティグループなどを設定 # ... }
file() 関数で静的なファイルを読み込んでいますが、templatefile() 関数を使えば Terraform の変数をファイルに埋め込むこともでき、より動的な設定が可能です。
おわりに
cloudinit Provider を紹介しました。紹介しているブログが他になさそうだったのでこの記事を書いたのですが、便利だと思うので使ってみてください。
参考
https://developer.hashicorp.com/terraform/tutorials/provision/cloud-initdeveloper.hashicorp.com
Nginx の公式 Docker イメージで /etc/resolv.conf のネームサーバーを resolver に使う方法
概要
Nginx の公式 Docker イメージを使用する際、コンテナの /etc/resolv.conf に記述されたネームサーバーを Nginx の設定ファイルで利用したい場合があります。本記事では、公式に提供されている機能でこの要件を満たす方法を解説します。
前提
Nginx の公式 Docker イメージの使用が前提です。
やり方
次の手順で設定します。
1. 環境変数 NGINX_ENTRYPOINT_LOCAL_RESOLVERS を設定する
コンテナ起動時に、環境変数 NGINX_ENTRYPOINT_LOCAL_RESOLVERS を設定します。この変数は定義するだけで機能するため、空文字でなければどのような値でも構いません (下記の例では true を設定しています)。
docker コマンドの引数で設定する場合、次のようなコマンドになります。
docker run -e NGINX_ENTRYPOINT_LOCAL_RESOLVERS=true -d nginx
2. 環境変数 NGINX_LOCAL_RESOLVERS を使う
手順 1. で環境変数 NGINX_ENTRYPOINT_LOCAL_RESOLVERS を定義すると、/etc/resolv.conf のネームサーバーの設定が環境変数 NGINX_LOCAL_RESOLVERS に設定されます。この変数は Nginx の設定ファイルで使用できます。
環境変数 NGINX_LOCAL_RESOLVERS を使用して resolver ディレクティブを設定すると次のようになります。
http { resolver ${NGINX_LOCAL_RESOLVERS}; # ... }
Nginx の設定ファイルに環境変数を埋め込んで使う方法は、公式ドキュメント を参照してください。
おわり
この機能はドキュメントに記載が見つからず、紹介しているブログ記事もなさそうだったので書きました。エントリーポイントスクリプトを読むのが一番わかりやすいと思います。下記にリンクを貼ったのでそちらも参考にしてください。
参考
- Issue: [Feature Request] Consider adding a script to import local resolver from /etc/resolv.conf #673
- 公式ドキュメント: nginx docker official image
/etc/resolv.confを読み取るエントリーポイントスクリプト: 15-local-resolvers.envsh- 環境変数を Nginx の設定ファイルに埋め込むエントリーポイントスクリプト: 20-envsubst-on-templates.sh
2024年の振り返り
2024 年を振り返ってよかったものをいくつか紹介します。
去年:
仕事
新卒2年目。
ロールは変わらず SRE ですが、9月ごろにチーム異動しました。全社横断的な SRE から Embedded SRE と呼ばれるチーム組み込みの SRE になりました。
7月には祇園祭と合わせて京都のオフィスに遊びに行きました。


本
『ベタープログラマ』
発売は 2024 年ではないけど、2024 年に読んだので紹介します。
今まで読んだ技術書の中でもかなりいい本でした。どうやって学ぶか、どういう姿勢でプログラミングに向かうかという話や、32章「完了したときが完了」にはタスクの完了を定義する、タスクを分解するといった仕事でも役立つ内容もあります。目次を見ればひと目でいい本だとわかってもらえるはず。
『この平坦な道を僕はまっすぐ歩けない』
ハライチ岩井のエッセイ。ラジオで『平坦道僕』と呼ばれてるやつ。収録されてる話はどれも好きだけど、1つ選ぶなら「高校生の僕と加藤と"もえたん"」かな。ラジオのトークにできるというのもあるかもしれないけど、30代になっても趣味を続けたり、新しいことに挑戦したりする生き方は憧れ。
ラジオ
オードリーのオールナイトニッポン
去年と変わらず聞いてます。東京ドームライブが今年あって、それに向けた YouTube 企画もあり熱が高まりました。現地は行けなかったけど、U-NEXT でのライブ配信を家で見ました。
それと、オールナイトニッポン JAM というオールナイトニッポンのサブスクに今年から入りました。この記事を書きながらオードリーの過去の放送を聞いているところです。音楽が当時のままではなかったり、トークがカットされていたり (ひどいと回そのものがカット) と少し残念なところもあったけど、入ってよかったサブスク。
アニメ
『機動戦士ガンダムSEED FREEDOM』
公開初日に観に行きました。幼少期から何度も見て脳に焼き付いたバンク・BGM が流れて最高でした。
ゲーム
『ARMORED CORE VI FIRES OF RUBICON』
発売は 2024 年ではないけど、2024 年にクリアしたので。
『Secret Level』というゲーム作品の映像化がアマプラで公開され、その中にアーマードコアもありました。そこで再燃し、年末には全実績解除までやりこみました。

おわりに
世代作品の新作やリメイクが増えていてそういう年代になったのか?という感じがします。来年は引っ越しで環境を変える予定なので、それを機にいろいろ挑戦したいところ。まずは外に出るところから。
それではよいお年を。
Renovateが作るPRの説明に任意のメッセージを挿入する
この記事は はてなエンジニア Advent Calendar 2024 の22日目の記事です。昨日は id:deflis55 さんの 「【SwiftUI】UIViewRepresentable の使い方とライフサイクルを理解する」 でした。
はじめに
Renovate が作る PR の説明 (description) に任意のメッセージを挿入する方法を紹介します。
次のページを参考にしました。
前提
Renovate をリポジトリにインストールしていることが前提です。
使ってみる
renovate.json に次のように prHeader、prFooter、prBodyNotes を設定します。
{ "$schema": "https://docs.renovatebot.com/renovate-schema.json", "prHeader": "> [!NOTE]\n> ここが prHeader", "prFooter": "> [!NOTE]\n> ここが prFooter", "prBodyNotes": "> [!NOTE]\n> ここが prBodyNotes" }
すると、Renovate が作る PR は次の画像のようになります。赤枠で囲った部分がそれぞれ今回挿入したメッセージです。

prHeader: 説明の冒頭にメッセージを挿入しますprFooter: 説明の末尾にメッセージを挿入しますprBodyNotes: テーブルの下にメッセージを挿入します
おわりに
私のチームでは prHeader にレビューのポリシーを書いています。例えば、「リリースノートを読んで破壊的変更があるか確認する」とメッセージを入れておけばレビューがスムーズになると思うのでおすすめです。
はてなエンジニア Advent Calendar 2024 の22日目の記事でした。明日の担当は id:fxwx23 さんです。
ISUCON14参加記 (最終スコア 10,285)
ISUCON14 にチーム「完璧な一日」で参加しました。技術サークルの友人2人とチームを組みました。
最終スコアは10,285でした。
関連:
オブザーバビリティ
OpenTelemetry を使ってオブザーバビリティのある状態を作りました。実際には十分なオブザーバビリティとは言えない様子だったのですが、最低限競技に使えるくらいにはなりました。
オブザーバビリティバックエンドは Honeycomb というサービスを使いました。
次のようなダッシュボードを作り、ボトルネックを探すのに役立てました。
例1. Nginx のリクエストを遅い順に並べる
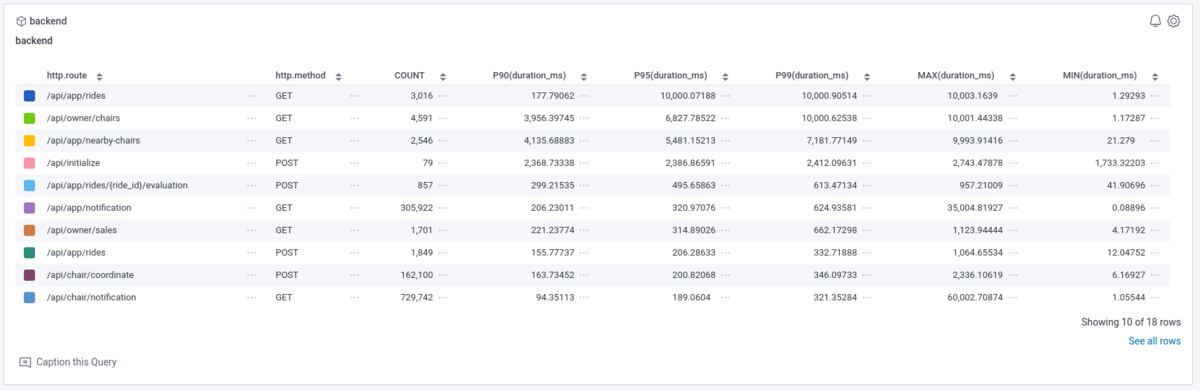
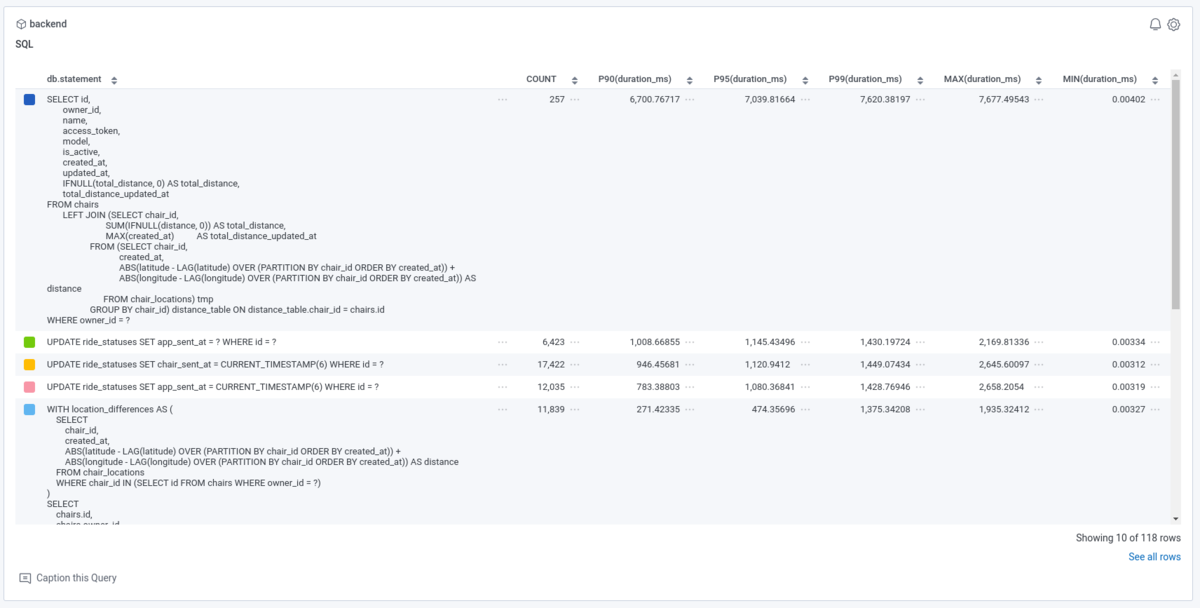
例2. MySQL クエリのダイジェストを遅い順に並べる
もちろん、これらの設定を当日準備するのは時間がかかるので、事前にコンフィグのスニペットを作ったり、Ansible で OpenTelemetry Collector をインストールできるようにしています。また、オーバーヘッドもあるので、競技終了直前に OpenTelemetry Collector のサービスは止めました。
サーバー構成
競技環境の3台のサーバーは次の構成にしました。
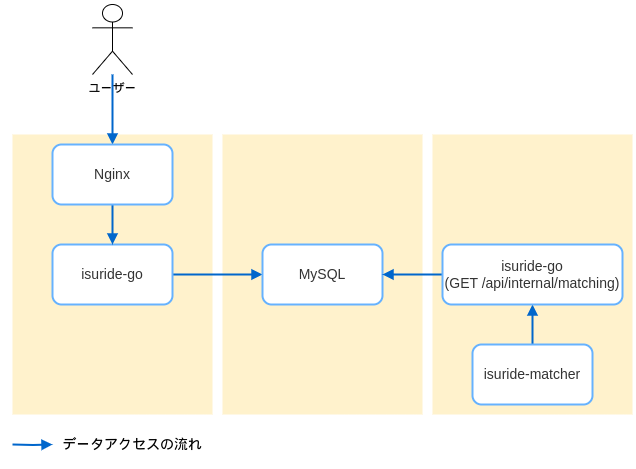
「サーバーは3台使えたほうがいいだろうから、すぐに分けられるところを分けよう」という方針でやったので、もっといいやり方がありそうです (MySQL を分けるとか) 。
やりたかったこと
大会本番にできなかったことは、MySQL でパフォーマンススキーマを使った分析です。OpenTelemetry の SQL Query Receiver と合わせてモニタリングできたら便利だったなと思っています。
例えば、実行したクエリについて rows_examined や rows_sent をモニタリングできると、問題あるクエリの発見が早くなるだろうと思ってます。
感想
競技環境はダッシュボードがかっこよかったですし、ベンチマークがすぐに実行されるのもよかったです。
個人的には、参加登録時点で OpenTelemetry を使いたいと思っていたので使えてよかったです。また、データベースに苦手意識があったのですが、今回の ISUCON を機に入門して苦手意識が減ったのもよかったです。
最後に、チーム組んでくれた2人に感謝。